记一次Redis内存暴涨的问题
Contents
现象
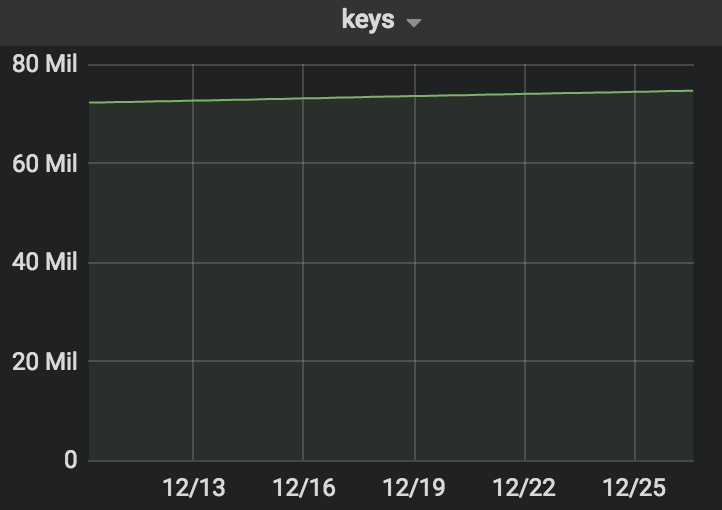
2018年12月15日开始,一个线上业务依赖的Redis内存陡增,但是Key的增长并没有明显变化。

排查思路与过程
- 第一反应,是不是上线导致的?立马查看了上线记录,发现问题时间点附近并没有上线。
- 第二反应,代码逻辑中之前隐藏的Bug,在某一时点爆发?经过梳理排除这一点。
- 最后,导出了一个端口的Key进行分析,发现也都是正常的。
这个时候笔者以为是有大量的用户被激活,接着联合产品同学制定产品策略,先控制住整体的写入量,保证服务可用。 我们通过一定的策略对全站用户进行过滤,把写入QPS降到之前的1/2,内存增长降低到原来的1/3。
稳住了战况后,看着监控上的增长曲线,还是觉得不太对劲。
于是去请教了架构组的Redis大牛,得知Redis在满足一定条件时会进行编码转换。
这个业务使用Redis的姿势是这样的:每个UID对应一个Hash,其中Field记录的是日期,如果用户每天都活跃,那对应的Field就会较多,从业务2017年8月上线到2018年12月已经有500多天,时间点刚好对的上。
|
|
联合DBA同学,调整参数进行验证,灰度一个端口,少了10G的内存占用。
至此,redis内存暴涨原因已经明确。
业务使用的是Hash类型,Redis存储的时候会采用ziplist进行内存压缩。
但是需要满足两个条件:
- Value <=
hash-max-ziplist-value - Field个数 <=
hash-max-ziplist-entries
其中第二条件不满足,Field个数超过了预设的值。导致Redis进行编码转换,放弃更省内存的ziplist采用了hashtable编码,从而导致了内存陡增。
原理说明
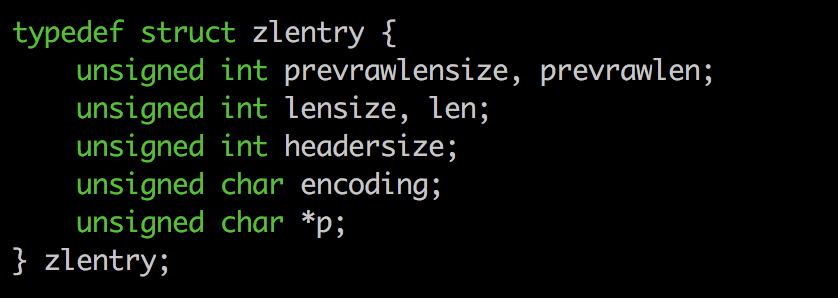
ziplist数据结构通过特殊的编码方式将数据存储在连续的内存中,其结构体如下:
hashtable节点结构体如下:

ziplist相比hashtable减少了内存碎片和指针的内存占用,是一种顺序型数据结构,但是速度不如hashtable,是一种时间和空间的权衡。
Author David
LastMod 2018-12-15